无监督表示学习 By 预测图片旋转
通过预测图片的旋转来进行无监督表示学习
摘要
在过去几年,DCNN因其学习高级语义特征的能力变革了计算机视觉领域。然而,为了成功地学习这些特征,通常需要大量的人工标注的数据,这通常是昂贵的且不可行的。
因此,大量的数据是否能够处理成功,无监督语义特征学习至关重要。
论文中,通过训练ConvNets来识别原始图像的2D旋转,从而学习图像特征。
论文中,从定性和定量两个方面展示了这个看似简单的任务实际上为语义特征学习提供了一个非常强大的监督信号。
论文中,在各种无监督的特征学习基准中对论文中提出的方法进行了详尽的评估,并且展示了其中所有最先进的性能。
具体来说,论文的结果在各个基准中都有极大的提升,优于无监督表示学习中的先进方法,从而显着缩小与有监督特征学习的差距。
例如,在PASCAL VOC 2007检测任务上,无监督预训练AlexNet模型实现了54.4%的mAP。将无监督特征学习迁移到其它任务中,得到了相似的结果。
介绍
最近几年,DCNN非常厉害。
DCNN通过大量的学习适合任务的视觉表示,达到了非常优秀的结果。例如,目标检测、语义分割、图片标题等。
然而,有监督特征学习受限于有标签的数据。近来学术界逐渐关注以无监督的形式,用ConvNet来学习高层表示,从而避免人工标注数据。其中,自监督学习(self-supervised learning)比较突出。
自监督学习定义了一个无标签的任务,通过对图像中存在的视觉信息的学习,为后面的特征学习提供监督信息。这种自监督学习的目的通常是“利用ConvNet学习得到可用于其他视觉任务的语义特征”。
通过上述自我监督学习获得的图像表示虽然不能与监督学习表示相匹配,但它们可以将学到的特征转移到其他视觉任务。
论文中首先定义了一组离散的几何变换,然后对数据集中的每张图片应用这些几何变换,将这些变换后的图片送入ConvNet模型中,从而训练网络识别这些变换。
这些几何变换实际上就是定义了分类任务。为了实现无监督的语义特征学习,选取恰当的几何变换至关重要。
论文中建议的几何变换是旋转图像0、90、180、270度。因此,ConvNet模型包含4-way图像分类任务来识别这四种旋转。
论文中提出的方法可以理解为:“如果不知道图像中描述的对象的概念,也不能识别它们的旋转”。
为了让模型具有识别旋转变换的能力,模型需要理解图片上物体的一些概念,例如位置、类型、姿态。

简单来说,将图片进行随机的几何变换作为ConvNet的输入,然后对ConvNet模型进行训练,使模型能够识别这些应用到图像上的几何变换,从而得到能够作为监督信息的语义特征。
论文的贡献:
提出了一种非常简单的自监督任务,同时能够为后面的语义特征学习提供监督信息。
在多种设置和多种视觉任务上,对论文中提出的自监督方法进行评估。
和先前的无监督方法相比,论文中的自监督学习方法有显著的提升。
对于几个重要的视觉任务,论文中的自监督学习方法显着地缩小了无监督和监督特征学习之间的差距。
模型
总览
论文的目标是:以一种无监督的方式,基于ConvNet学习语义特征。为了实现目标,训练ConvNet模型F(.)来估计应用到输入图像上的几何变换。
论文中定义了一组K个离散几何变换G={g(.|y)}_y=1_K,g(.|y)表示将第y种几何变换应用到图片上的操作,这种操作产出变换后的图片X_y=g(X|y)。
模型F(.)以X_y∗作为输入,输出所有几何变换的概率分布:F(X_y∗|θ)={F_y(X_y∗|θ)y=1_K。其中,F(X_y∗|θ)是预测的概率,y∗是几何变换的标签,模型F(.)并不知道,θ为模型F(.)的参数。

选择几何变换:图像旋转
定义一个对几何变换G分类的任务,迫使ConvNet模型学习对其他视觉任务有用的语义特征。
论文中推荐定义一组几何变换G:按0、90、180、270度旋转图片。
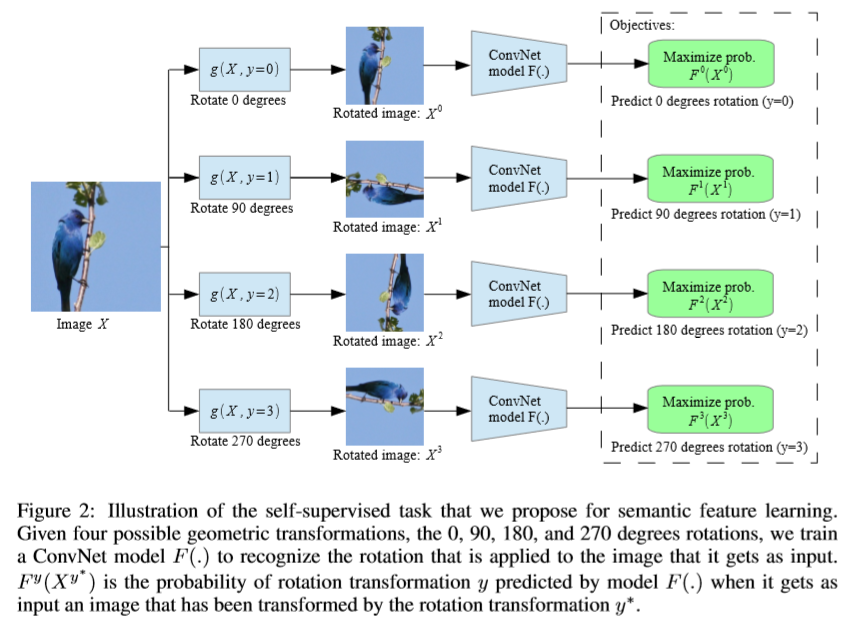
Rot(X,φ)定义为将图片X旋转φ度。那么,K(=4)种图片旋转G={g(X|y)}_y=1_4,其中g(X|y)=Rot(X,(y-1)*90)。
迫使网络学习语义特征
该方案可行的直觉是ConvNet模型基本上不可能有效地识别旋转,除非它首先学会识别和检测图像中的对象及其语义部分。
为了预测图片的旋转,ConvNet必须学习对象的位置、认识它们的方向和对象类型。
下图是对模型生成的attention maps的可视化:

可以发现,为了实现对旋转的预测,模型学习关注高级对象部分。对比监督模型和无监督模型,发现它们都关注相同的区域。
下图是对第一层卷积核的可视化:

它们在多个方向和多个频率上具有多种边缘卷积核。而且,这些卷积核似乎比有监督识别任务学到的卷积核有更多的变化。
缺少低级视觉组件
Well-posedness
人类通常观察固定的方向,这使得很容易识别出图片是否旋转,且几乎没有歧义。
实现图片的旋转
使用flip和transpose操作来实现图片的旋转。
对于0度旋转,不作处理。
对于90度旋转,先转置再垂直翻转。
对于180度旋转,先垂直翻转再水平翻转。
对于270度旋转,先垂直翻转再转置。
讨论
- 和有监督相比,训练时间大致相同,收敛速度相似,也可并行训练。
- 和其他的无监督或自监督一样,为了避免学习细小(trivial)的特征,不需要预处理。
- 和无监督特征学习基线相比,通过这种方式特征学习有了极大的提高。
实验结果
这一部分:
- 在常见的数据集上进行评估,包括CIFAR-10、ImageNet、PASCAL、Places205等。
- 在常见的任务上进行评估,包括对象检测、对象分割、图像分类。
- 也考虑了其他的学习场景,包括迁移学习、半监督学习。
如何评估无监督学习的特征?
以学到的特征和原始图像的标签为输入,训练一个“非线性的分类器”,从而得到“分类准确率”。
CIFAR实验
实现细节
使用Network-In-Network架构
SGD + 批次大小128 + momentum 0.9 + weight decay 5e-4 + lr 0.1
训练100代,在30、60、80代时按因子5降低学习率
将4种旋转的图片在同一批送入网络会有明显的性能提高
评估学习特征的层次
按照深度探索学习到的特征的质量。
分类器:3个全连接、2个包含200个特征通道的卷积层,每个卷积层后面有BN层和ReLU单元。
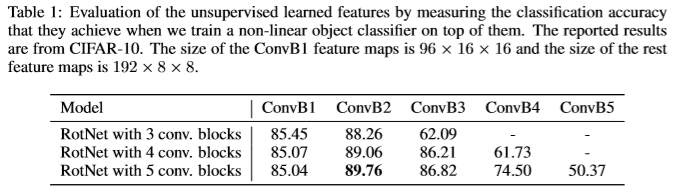
从图中发现,从第二个卷积模块之后准确率下降。论文中认为这是因为后面的卷积层更加关注识别旋转的任务,而不是专注特征提取。
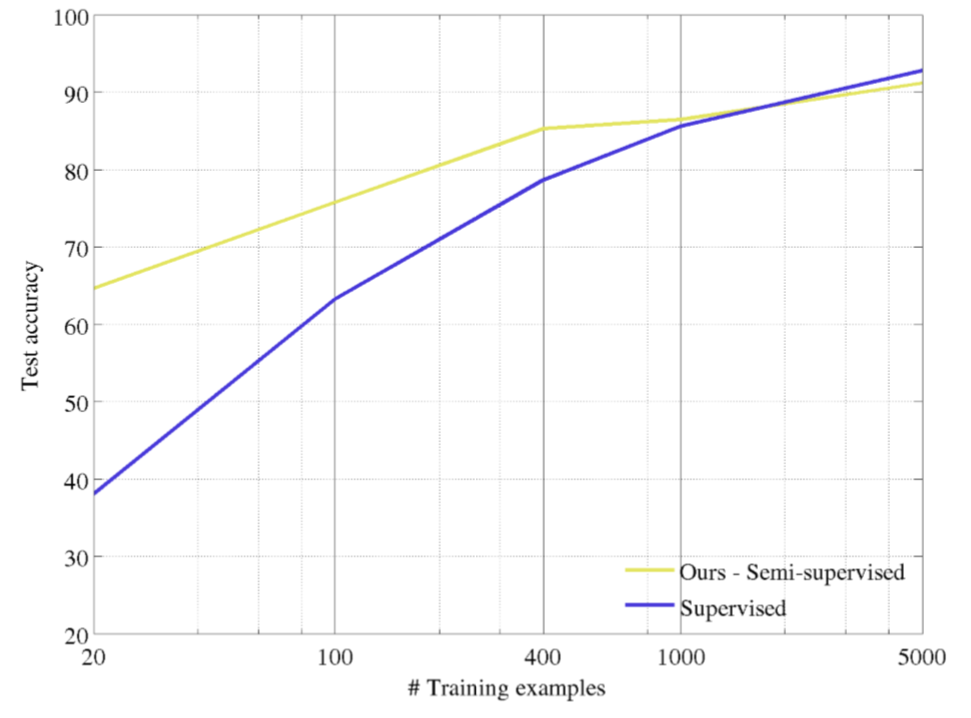
半监督
经过特征学习后,再使用一小部分图片和标签进行有监督学习。
从图中的对比试验可以看出,学习的特征还是有效果的:
结论
论文中提出了一个新的自监督特征提取学习:训练一个能够识别图像旋转的ConvNet模型。
显著地提高了无监督特征学习的性能。
扩展
对于匀质区域,旋转前和旋转后差别不大,经过网络之后应该尽量识别为不旋转。
对于聚集区域,旋转前和旋转后差别也不大,唉,PASS。
